-
장애 해결: 부하 원인 찾기글또 2025. 3. 2. 23:21
들어가며
안녕하세요.
앞으로 두 편의 글에서는 Kafka를 기반으로 한 서비스에서 특정 시각에 트래픽이 집중되면서 발생하는 장애 현상과 그 해결 방법에 대해 이야기해보려 합니다.
현재 장애 복구를 위한 retry 정책은 적용되어 있지만, 근본적인 문제 해결을 위해서는 보다 구조적인 접근이 필요했습니다.오늘은 그 원인을 분석해보겠습니다.
문제 상황

A 서비스의 데이터가 B, C 서비스로 전달되면서 데이터베이스(DB)에 저장되는 과정에서 부하가 발생합니다.
이러한 구조에서는 DB가 전체 시스템의 병목이 될 수 있으며, 실제로 부하로 인해 쿼리 처리 속도가 늦어지고 timeout 현상이 발생하는 문제가 관찰되었습니다.
특히 slow 쿼리 로그에서 커밋이 다수 노출되었는데, 이는 DB에 많은 요청이 몰리면서 커밋 처리 속도가 병목에 다다랐기 때문으로 보입니다.
원인 분석: 시스템 자원 사용 분석
장애의 원인을 파악하기 위해 장새 시점의 여러 시스템 지표를 확인해 보았습니다.
메모리 사용량

메모리 사용량은 안정적으로 유지되고 있었으며, 메모리 부족으로 인한 문제는 아니었습니다.
네트워크 트래픽


22:02분까지 네트워크 byte 입출력 차이가 적었고, 초당 50KB의 바이트 전송량과 120 p/s의 패킷 전송량을 보면, 평균 패킷 크기는 약 416바이트(즉, 400~420바이트)로 계산됩니다. 이는 대량의 데이터를 전송하는 것이 아니라 비교적 작은 크기의 패킷들이 다수 전송되고 있음을 의미합니다.
디스크 I/O

diskio_read_time은 거의 0에 가까워 읽기 작업에는 문제가 없음을 확인했습니다.
diskio_write_time이 0.5ms(단위 시간당)로 나타나고, 전체 I/O 처리 시간인 diskio_io_time은 0.3ms 정도로, 디스크 쓰기 작업에 소요되는 시간이 극히 짧습니다.실제 전송되는 데이터량은 읽기는 미미하고, 쓰기는 약 2.55 KiB/s 정도입니다.
디스크 I/O 자체는 빠른 속도를 보이고 있어 문제의 주요 원인으로 보기는 어렵습니다.
CPU 사용률 및 I/O 대기
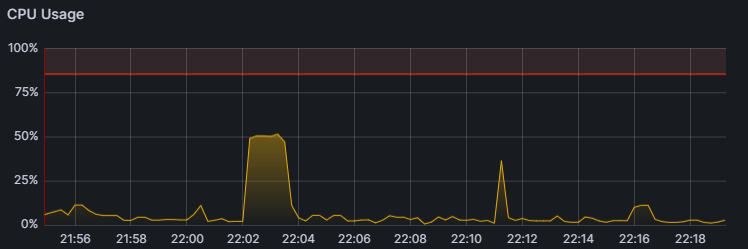
전체 CPU 사용률은 idle 시간을 제외하면 약 50% 정도 사용되고 있었습니다.
지표를 구성하는 필드를 살펴보니 user와 system의 비중은 낮은 반면, cpu_iowait의 비중이 높게 나타났습니다.
I/O Wait
I/O wait 시간이 높게 나타난 것은 디스크 쓰기 자체는 빠르지만, DB에 다수의 쿼리 요청과 커밋 작업이 몰리면서 특정 CPU 코어에 부하가 집중되어 I/O 작업이 완료되기를 기다리는 시간이 늘어났기 때문으로 추정됩니다.
하지만 높은 I/O wait 값이 반드시 디스크 I/O 병목 현상을 의미하는 것은 아닙니다.
I/O wait는 CPU가 실제 작업을 수행하지 않고 I/O 작업이 완료되기를 기다리는 시간의 비율을 나타냅니다.
CPU 성능이 크게 향상되면 전체 거래 시간 중 I/O가 차지하는 비율은 자연스럽게 높아질 수 있습니다.
즉, 디스크 응답시간 자체에는 문제가 없더라도, CPU가 더 빨라진 환경에서는 I/O wait 값만 높아 보일 수 있으며, 이는 오히려 전체 처리 속도가 빨라졌음을 반영하는 정상적인 현상일 수 있습니다.
위에서 디스크 I/O자체는 빠른 속도를 보여줬으므로 문제의 원인이 아닐 수 있습니다.해결 방안 및 예방 조치
DB 단에서의 문제를 해결하기 위해서는 단기적인 장애 복구(retry) 외에도 커밋 처리 속도를 향상시킬 수 있는 설정과 아키텍처 개선이 필요합니다.
몇 가지 고려할 수 있는 해결 방안은 다음과 같습니다.
쿼리 분산 및 배치 처리
동시에 몰리는 쿼리 요청을 분산하거나, 배치 처리를 통해 단위 시간당 처리해야 할 쿼리 수를 줄이는 방법을 고려할 수 있습니다.
하드웨어 자원 확장
CPU 코어에 부하가 집중되는 문제를 완화하기 위해, CPU 스케일 아웃(멀티 코어 확장)이나 DB 서버 클러스터링을 통한 부하 분산 전략을 도입할 수 있습니다.
마무리
메모리, 네트워크, 디스크 I/O 측면에서는 큰 문제가 없었으나, 다수의 쿼리 요청과 커밋 작업이 몰리는 시점에 장애가 발생하는 것은 경험을 했습니다.
아직 만족할 만한 근본 원인을 찾지는 못했지만, 향후 쿼리 분산 및 배치 처리 기법 도입을 통해 문제를 해결해볼 예정입니다.
다음 글에서는 이러한 해결 방법들을 구체적으로 구현하는 방법에 대해 다루겠습니다.
감사합니다.'글또' 카테고리의 다른 글
글또 10기 소감 (0) 2025.03.29 DB 장애 분석: Galera Cluster Segfault (1) 2025.01.31 개발자를 위한 커리어 관리 핸드북 (0) 2025.01.04 2024 회고 (0) 2024.12.22 Galera Cluster 알아보기 (0) 2024.12.20