-
Galera Cluster 알아보기글또 2024. 12. 20. 18:05
0. 들어가며
안녕하세요.
이번에는 Galera Cluster에 대해 알아보려고 합니다.
회사 내부에서 Galera Cluster를 사용하고 있는데, 사용해 보니 특색 있는 Clustering 방식이며 잘 모르고 사용해서는 안 되는 기술이라는 생각이 들어서 공부하게 되었습니다.
제가 궁금했던 점과 에러를 파악하며 공부했던 내용을 정리합니다.
글의 순서는 다음과 같습니다.- Galera cluster 소개
- Replication 방법
- 인증 복제
- 비동기 복제
- DeadLock
- Large Transaction
- DDL 복제 방식 (Schema Upgrades)
- Cluster join 시 이뤄지는 일들 (State Snapshot Transfers)
- SST, IST
- Crash 대응 방안
- Health check
- 마무리
1. Galera cluster 소개

Galera Cluster는 MariaDB의 Clustering 방법 중 하나입니다.
Galera Cluster의 가장 큰 특징은 Multi-Master 구조의 복제 구조라는 것입니다.
모든 기술이 그렇듯 Galera Cluster에도 장점과 단점이 있습니다.
큰 장점 중 하나는 노드 다운 시 장애 시간이 0에 가깝다는 점입니다.
Multi-Master라서 하나가 죽어도 다른 Master가 있기 때문에 고가용성을 지킬 수 있습니다.
또 모든 노드에서 읽기와 쓰기가 가능하기 때문에 부하를 효과적으로 분산할 수 있습니다.
그러나 단점도 존재합니다.
Galera Cluster는 리눅스 및 유닉스 계열 OS와 InnoDB 엔진에서만 구동이 가능합니다(실험적으로 MyISAM과 Aria도 지원한다고 합니다).
신규 노드가 Cluster에 추가될 때 복제 시간이 오래 걸릴 수 있습니다.
그렇다 보니 가용성에서는 높은 장점을 띄지만 확장성에서는 안 좋은 결과를 나타냅니다.
또한, 완전 동기화 복제 방식이 아니기 때문에 Stale Read 문제가 발생할 수 있습니다.
Multi-Master 구조에서 데이터 정합성을 유지하기 위해 Deadlock 에러가 빈번하게 발생할 수 있습니다.
이러한 단점들은 아래에서 좀 더 자세히 다뤄보겠습니다.2. Replication 방법
인증 복제 (Certification-Based Replication)
https://galeracluster.com/library/documentation/certification-based-replication.html
Multi-Master 구조이다 보니 Galera Cluster에서는 양방향 복제가 이뤄져야 합니다.
Galera에서는 인증 기반의 복제(Certification-Based Replication)를 사용합니다.
여기서 인증이란 트랜잭션 커밋 이후, 발생 노드가 다른 마스터 노드에게 복제가 가능한지 동기적으로 문의하는 과정을 의미합니다.
이를 통해 모든 노드가 같은 상태를 유지할 수 있다는 것을 보장받습니다.
인증 복제 과정을 보면 다음과 같습니다:- 사용자가 커밋을 합니다.
- 각 노드로 writeset이 복제됩니다. GTID를 결정합니다.
- GTID는 galera 복제 프로세스에서 사용되는 것으로 상태변경의 글로벌한 고유 식별자입니다.
- writeset은 복제할 데이터베이스 행과 트랜잭션 중 보유한 lock에 대한 정보를 담고 있습니다
- 모든 노드에서 인증을 진행합니다.
- 인증에는 wsrep replication plugin(Galera Replication Plugin)과 writeset이 사용됩니다.
- wsrep replication plugin은 실질적인 복제 관련 API입니다.
- wsrep replication plugin을 통해 발신자 노드에서 수신자 노드로 writeset이 복제되면, 수신자 노드는 writeset이 노드에 적용할 수 있는지 검사합니다.
- 인증이 성공하면 queue에 writeset을 적재합니다.
- 실패하면 복제 노드는 writeset을 삭제합니다. 원천 노드는 롤백됩니다.
- slave thread가 비동기적으로 queue를 비우며 데이터를 반영합니다.
마지막 커밋된 트랜잭션 id와 인증에 사용되는 트랜잭션 id 사이는 무엇이 있을까?
그 구간에 있는 트랜잭션들은 이미 전파되어 트랜잭션id를 배정받았지만, 아직 인증되지 않은 트랜잭션들이다.
https://severalnines.com/blog/improve-performance-galera-cluster-mysql-or-mariadb/ + 로컬 트랜잭션과 rollbacker thread
galera 에서 로컬 트랜잭션은 인증 대상이 아니지만,
applier thread가 write-set을 적용하려는 시점에 해당 row를 로컬 트랜잭션이 점유 중이면
로컬 트랜잭션은 무조건 rollback 대상이 되고, rollbacker thread가 이를 강제로 종료한다.
PK
인증은 writeset 안의 기본 키(PK)를 기반으로 이루어지기 때문에, PK 값이 없는 테이블을 생성했다면 제약사항이 발생합니다.
PK가 없으면 delete가 불가능하고, 노드별로 행 순서가 달라지는 문제가 생길 수 있습니다.
wsrep_certify_nonPK라는 설정값 덕분에 PK가 없을 경우에도 동작하지만, 이는 권장되지 않습니다.
PK가 없는 테이블에서 delete 시 테이블 Full scan을 하게 됩니다.
PK를 생성하는 것이 기본 설정이며, 더 안전하고 효율적입니다.
노드가 여러 개일 때 PK 값은 노드별로 다른 auto increment 규칙을 가져야 합니다.
노드가 동일한 ID를 생성한다면 인증의 의미가 없어지고, Deadlock이 발생할 것입니다.
따라서 노드 간 PK가 겹치지 않도록 auto increment 값을 배수 단위로 생성됩니다.
- 노드 1: 1, 4, 7,...
- 노드 2: 2, 5, 8,...
- 노드 3: 3, 6, 9,...
이러한 설정을 통해 노드 간 PK 충돌을 방지하고, Deadlock 발생을 줄일 수 있습니다.
- https://www.percona.com/blog/how-missing-primary-keys-break-your-galera-cluster
- https://forums.percona.com/t/primary-key-on-a-galera-cluster/6562/5
- https://severalnines.com/blog/improve-performance-galera-cluster-mysql-or-mariadb
- https://www.percona.com/blog/how-missing-primary-keys-break-your-galera-cluster
- https://bugs.mysql.com/bug.php?id=53375
2-1. 비동기 복제
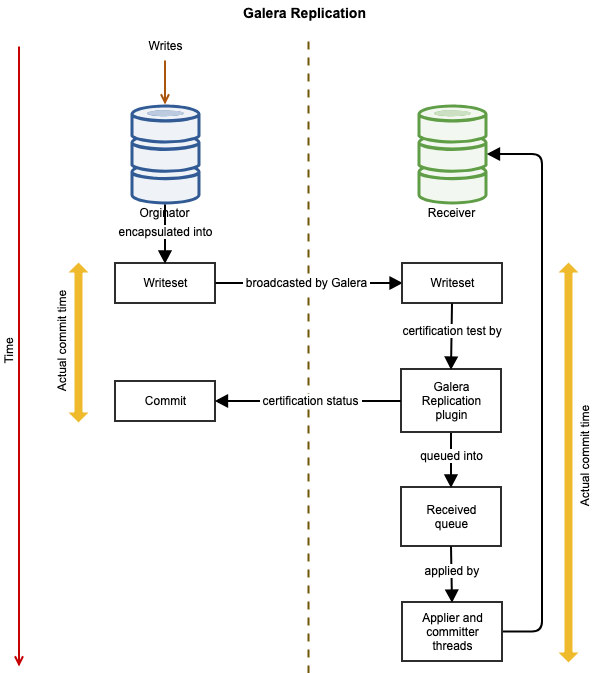
https://severalnines.com/blog/ha-mysql-and-mariadb-comparing-master-master-replication-galera-cluster/
Galera의 인증 기반 복제는 데이터 인증을 동기적으로, 실질적인 데이터 복제를 비동기로 처리하는 Virtually Synchronous Replication입니다.
복제 이후 인증이 완료된 writeset은 테이블 스페이스에 값이 바로 써지지 않고 노드의 receive queue에 적재되며, 이 큐는 Slave Threads에 의해 비동기로 실행되고 비워집니다.
Slave Threads의 수는 설정할 수 있습니다.
Slave Threads는 병렬로 writeset을 실행하지만, 일관성 문제가 자주 발생한다면 1로 설정하면 도움이 될 수 있습니다.
IST(Incremental State Transfer)의 경우 Joiner 상태일 때 Slave Threads의 수에 따라 더 빠르게 데이터를 따라잡을 수 있습니다.
- https://galeracluster.com/library/kb/multi-master-conflicts.html
- https://www.percona.com/blog/percona-xtradb-cluster-multi-node-writing-and-unexpected-deadlocks/
- https://planet.mysql.com/entry/?id=35366
- https://mariadb.com/kb/en/about-galera-replication/#galera-slave-threads
- https://www.percona.com/blog/understanding-multi-node-writing-conflict-metrics-in-percona-xtradb-cluster-and-galera/
2-2. Lost Update, DeadLock
단일 노드

one node
Galera에서도 동일한 노드에서 두 트랜잭션이 실행되면 REPEATABLE READ 격리 수준에서 Lost Update가 발생할 수 있습니다.
이를 방지하려면 단일 노드에서 Lock을 잡아야 합니다.
다중 노드

multi node
다른 노드에서 두 트랜잭션이 실행될 경우 Lost Update는 발생하지 않지만 Deadlock 에러가 발생합니다.
이는 전통적인 자원 경합으로 인한 Deadlock과는 다릅니다.
Galera Cluster는 전 노드에 걸쳐 Lock을 잡지 않기 때문에 같은 자원을 다른 노드에서 수정할 수 있습니다.
이 경우 Deadlock 예외를 발생시키고, First Committer Wins 전략에 따라 첫 번째로 커밋한 트랜잭션이 성공하고 두 번째 트랜잭션은 실패합니다.
이를 통해 Lost Update를 예방할 수 있습니다.
공식 문서에 따르면, 이러한 선택은 드물게 발생하는 상황을 위해 항상 Cluster 성능을 저하시킬 필요가 없기 때문입니다.
업데이트가 필요하지만 Deadlock이 발생한 경우 재시도가 필요할 수 있습니다.
이는 wsrep_retry_autocommit 설정 값을 통해 조절할 수 있습니다.
- https://severalnines.com/blog/improve-performance-galera-cluster-mysql-or-mariadb
- https://galeracluster.com/library/documentation/overview.html
- https://galeracluster.com/library/documentation/certification-based-replication.html
- https://mariadb.com/kb/en/about-galera-replication/#galera-slave-threads
- https://galeracluster.com/library/kb/parallel-applier-threads.html
- https://severalnines.com/blog/ha-mysql-and-mariadb-comparing-master-master-replication-galera-cluster/
- https://galeracluster.com/library/kb/multi-master-conflicts.html
- https://galeracluster.com/library/kb/deadlock-found.html
- https://galeracluster.com/2015/09/support-for-mysql-transaction-isolation-levels-in-galera-cluster
2-3. Large transaction
단점: Lost Update
개발 시 트랜잭션을 길게 가져가는 것은 커넥션 소비와 많은 데이터 변경을 초래하므로 바람직하지 않습니다.
Galera Cluster에서도 트랜잭션의 크기를 작게, 변경되는 데이터 수가 적게 유지하는 것이 유리합니다.
변경된 데이터가 많으면 복제 시간이 길어져 비동기 복제 특성상 노드 간 데이터 차이가 발생할 수 있습니다.
인증 완료 후 복제 이전에 사용자가 복제 노드에서 조회하면 데이터 불일치, 즉 Stale Read가 발생할 수 있으며, 이는 Lost Update로 이어질 수 있습니다.
단점: DeadLockhttps://galeracluster.com/library/documentation/certification-based-replication.html
커밋 시 인증 절차를 통해 해당 트랜잭션이 적용될 수 있는지 검사해야 하며, 변경되는 데이터가 많다면 다른 트랜잭션과 충돌하여 Deadlock이 발생할 수 있습니다.
Deadlock이 발생하면 많은 시간을 소비한 후 데이터 변경이 이루어지지 않아 사용자가 불편을 겪고, DB는 롤백을 해야 하므로 리소스가 낭비됩니다.
MySQL에서 롤백은 커밋 작업보다 느리고 덜 최적화된 작업입니다.
변경의 크기도 wsrep_max_ws_rows와 wsrep_max_ws_size에 의해 제한됩니다.
writeset의 허용 row와 byte size (기본값 2GB)를 초과하면 writeset이 거부됩니다.
많은 데이터 변경이 필요하다면 해당 설정을 확인해야 합니다.
트랜잭션을 작게 유지하는 것이 좋지만, 어쩔 수 없이 크게 유지해야 한다면 Lost Update와 Deadlock을 피할 수 있는 몇 가지 방법이 있습니다.
1. Streaming Replication
Galera 4에 추가된 Streaming Replication은 트랜잭션이 처음 인증 절차를 거친 후, 변경되는 데이터를 각 노드에 점진적으로 복제하는 방식입니다.
분산되는 데이터는 byte, row, statement 등으로 설정할 수 있으며, 이를 통해 Cluster 전역에 락을 거는 효과를 누릴 수 있습니다.
모든 노드에 영향을 미치므로 세션 단위로 사용하는 것을 추천합니다. 롤백 가능성이 있는 트랜잭션에서는 주의가 필요합니다.
2, wsrep_sync_wait 설정
wsrep_sync_wait 설정을 통해 read 전에 동기화 여부를 확인할 수 있습니다.
이 설정을 활성화하면, read 작업 전에 동기화가 완료될 때까지 대기하여 데이터 일관성을 유지할 수 있습니다.
3. Write node 한 대만 유지
Write 노드를 한 대만 유지하면 모든 노드에 걸쳐 락을 잡는 문제를 피하고, Lost Update를 방지할 수 있습니다. 모든 쓰기 작업이 한 노드에서 이루어지기 때문에, 데이터 일관성을 보다 쉽게 유지할 수 있습니다.
- https://severalnines.com/blog/guide-mysql-galera-cluster-streaming-replication-part-one
- https://severalnines.com/blog/guide-mysql-galera-cluster-streaming-replication-part-two
2-4. DDL 복제 방식 (Schema Upgrades)
Galera Cluster에서 DDL(데이터 정의 언어) 복제는 트랜잭션 복제와는 다른 방식으로 이루어집니다.
DDL 복제 방식에는 TOI, RSU, Non-blocking 방식이 있습니다.
기본 설정은 TOI 방식입니다
TOI (Total Order Isolation)
TOI 방식에서는 쿼리 실행 전 각 노드에게 쿼리(statement)를 복제합니다.
각 노드는 쿼리를 직접 실행합니다. 이 방식의 주요 특징은 다음과 같습니다.
- 쿼리 실행 전 대기: 쿼리 실행 전에 들어온 트랜잭션이 끝날 때까지 기다립니다.
- 트랜잭션 블로킹: 쿼리가 실행되는 동안 모든 트랜잭션이 블로킹됩니다. 이 블로킹은 노드 단위로 이루어집니다.
- 서버 단위 복제: Galera Cluster는 서버 단위의 복제만 지원하므로, 서버 하나에 여러 데이터베이스를 두면 DDL 시 다른 데이터베이스에도 영향 줍니다.
- 동기 복제의 한계: 쿼리 실행 중 특정 노드가 죽는다면 테이블 불일치가 발생할 수 있습니다. 이를 해결하기 위해 SST(State Snapshot Transfer) 방식을 통해 복구해야 합니다.
여기서 가장 주요 깊게 봐야 하는 것은 트랜잭션 블로킹입니다.
부하가 큰 DDL을 사용했다면 Cluster 전체 성능에 영향을 미칠 수 있고 전체 Cluster 장애로 이어질 수 있습니다.
RSU (Rolling Schema Upgrade)
RSU 설정은 TOI의 최대 단점인 트랜잭션 블로킹을 해결할 수 있습니다.
RSU 방식에서는 노드를 하나씩 Cluster에서 분리하여 쿼리를 실행한 후 다시 Cluster에 참여시키는 방식입니다.
이 방법의 주요 특징은 다음과 같습니다.
- 블로킹 없음: RSU 방식에서는 트랜잭션 블로킹이 발생하지 않습니다.
- 변경 전후 테이블 공존: 잠시 동안 변경 전 테이블과 변경 후 테이블이 공존하게 됩니다.
NBO (Non-Blocking Operations)
NBO는 Galera Cluster Enterprise Edition에서 사용할 수 있는 기능입니다.
돈 내고 써야 하는 만큼 간단히 넘어가겠습니다.
TOI 방식의 개선된 형태로, 몇 가지 주요 특징이 있습니다.
- 부분 블로킹: TOI와 마찬가지로 쿼리가 각 노드로 복제되고 트랜잭션이 블로킹되지만, 변경 중인 테이블을 제외하고는 데이터 삽입이 가능합니다.
- 향상된 성능: TOI 방식에 비해 더 나은 성능을 제공합니다.
3. Cluster join 시 이뤄지는 일들 (State Snapshot Transfers)
Cluster에 신규 노드가 참여할 때 데이터 복제가 필요합니다.
이를 위해 Galera Cluster는 State Snapshot Transfers(SST) 방법을 통해 데이터를 복제합니다.
데이터 제공 노드는 donor, 데이터를 받는 노드는 joiner라고 합니다.
Donor 노드를 선택할 때는 Group Communications Module이 다양한 상태를 판단합니다.
wsrep_sst_donor 설정을 통해 특정 노드를 지정할 수 있습니다.
IST (Incremental State Transfer)
IST는 Cluster에 신규 노드가 참여할 때 변경된 트랜잭션만 보내는 방법입니다.
IST 방법이 항상 사용되는 것은 아니며, 특징은 다음과 같습니다.- gCache: Cluster에서 트랜잭션을 일부 저장해 두는 공간입니다. Joiner 노드가 가장 마지막으로 가지고 있는 트랜잭션 ID가 gCache에 있다면 IST를 사용합니다.
- gCache 크기: gCache를 적절한 크기로 설정하는 것이 중요합니다. DB 크기보다 크게 잡으면 SST와 성능 차이가 없습니다.
- Donor 노드: IST 과정 중에도 읽기와 쓰기가 가능합니다.
- 복제 속도: WriteSet을 보내는 방식이므로 Slave Threads 수를 늘리면 복제 속도가 향상됩니다
노드가 자주 죽어 노드 재진입이 잦다면 gCache의 크기를 적절하게 설정해서 SST를 사용하지 않도록 하는 것이 좋습니다.
SST (State Snapshot Transfer)
SST는 Cluster에 신규 노드가 참여할 때 모든 데이터를 전송하는 방법입니다.
이는 IST보다 느릴 수밖에 없으며, 다음과 같은 특징이 있습니다.- 읽기 락: SST 과정 중 donor는 읽기 락이 걸려서 쓰기가 불가능합니다. 이 때문에 Cluster는 최소 3대의 서버로 유지하는 것이 좋습니다.
- 쿼럼: 서버 수가 2대인 경우, 쓰기가 불가능하므로 최소 3대의 서버를 유지해야 합니다.
- 논리적인 복제: mysqldump 등을 사용합니다.
- 물리적인 복제: rsync, xtrabackup 등의 방법을 사용합니다.
다음은 replication DB를 운영할 때 필요한 정보입니다.
Replication DB (binlog)
Galera Cluster를 사용하더라도 기존의 replication DB를 운영해야 할 경우가 있을 수 있습니다.
Galera는 기존 MySQL replication과는 다르게 binlog를 통한 복제가 아닙니다.
각 노드에서 이루어지는 액션만 binlog에 기록됩니다.
Replication DB를 Galera와 함께 사용하려면 binlog를 활성화해야 하며, 이를 위해 log_slave_updates=ON 설정을 해야 합니다.
이렇게 하면 WriteSet도 binlog에 기록되어 replication DB를 설정할 수 있습니다.
- https://mariadb.com/kb/en/using-mariadb-replication-with-mariadb-galera-cluster-using-mariadb-replica/#configuring-a-cluster-node-as-a-replication-master
4. Crash 대응방안
운영 중 불의의 사고로 인해 모든 DB가 크래시(crash) 나서 다운될 수 있습니다. 이때의 대응 방안은 다음과 같습니다.
모든 노드가 내려갔다면 가장 마지막 노드를 찾아서 donor로 띄우고 나머지는 노드를 붙여야합니다.
가장 마지막 노드 찾기
크래시 발생 시 가장 중요한 것은 가장 최근에 동작했던 노드를 찾아서 그 노드를 donor로 사용하는 것입니다. 이를 통해 데이터 손실을 최소화하고 복구 시간을 단축할 수 있습니다.
- DB 접속이 불가능할 때
- 아래 명령어 중 하나를 실행시켜 가장 큰 값의 노드를 찾아야 합니다.
- {userPath}/mariadb/data/grastate.dat의 값을 확인해 가장 큰 seqno를 가진 노드가 donor가 되어야 합니다.

- 만약 위의 seqno의 값이 -1이라면
- {userPath}/service/mariadb/bin/mysql —wrep-recover 명령어를 통해 seqno의 값을 확인해야 합니다.

- {userPath}/service/mariadb/bin/mysql —wrep-recover 명령어를 통해 seqno의 값을 확인해야 합니다.
- {userPath}/mariadb/data/grastate.dat의 값을 확인해 가장 큰 seqno를 가진 노드가 donor가 되어야 합니다.
- 아래 명령어 중 하나를 실행시켜 가장 큰 값의 노드를 찾아야 합니다.
- DB 접속 가능할 때
- 아래 명령어 중 하나를 실행시켜 가장 큰 값의 노드를 찾아야 합니다.
- SHOW STATUS LIKE 'wsrep_last_committed';
- SELECT @@global.gtid_binlog_pos;
- bin log 크기 비교 ( log_slave_updates가 켜져 있을 경우에만 확인)
- 아래 명령어 중 하나를 실행시켜 가장 큰 값의 노드를 찾아야 합니다.
- Donor 노드 부팅:
- 가장 마지막 노드를 부팅하여 Cluster의 첫 번째 노드로 설정합니다.
- {userPath}/mariadb/data/grastate.dat의 safe_to_bootstrap의 값을 1로 바꾼 후 start_cluster를 실행합니다
다른 방안으로는 수동으로 데이터를 복구 시키고 클러스터에 붙이는 방법도 있습니다.
이 방법을 사용해본 결과 데이터 복제 시간만 걸리고 클러스터에는 IST로 빠르게 합류할 수 있었습니다.
Manual SST of Galera Cluster Node With Mariabackup
It can be helpful to perform a "manual SST" with Mariabackup when Galera's normal SSTs fail.
mariadb.com
5. Health checkHealth check는 아래 프로젝트를 활용하여 진행할 수 있으며, 9200 포트를 통해 health check를 수행합니다.
단순히 DB 실행 여부만 판단하는 것이 아니라, wsrep_local_state 값을 기반으로 상태를 확인합니다.

https://github.com/cloudfoundry/pxc-release/blob/main/src/github.com/cloudfoundry-incubator/galera-healthcheck/healthcheck/healthcheck.go pxc-release/src/github.com/cloudfoundry-incubator/galera-healthcheck at main · cloudfoundry/pxc-release
BOSH release of Percona Xtradb Cluster . Contribute to cloudfoundry/pxc-release development by creating an account on GitHub.
github.com
- https://galeracluster.com/library/documentation/crash-recovery.html
- https://dba.stackexchange.com/questions/157500/how-to-recover-mariadb-galera-cluster-after-full-crash
- https://galeracluster.com/documentation/html_docs_remove-snapshot-isolation-from-faq/galera-documentation.pdf
- https://lob-dev.tistory.com/76
- https://cirius.tistory.com/1768
- https://fromdual.com/limitations-of-galera-cluster
- https://severalnines.com/resources/whitepapers/galera-cluster-mysql-tutorial
6. 마무리
Master-Slave 구조만 접하다가 Master-Master 구조를 보니 신기했습니다. 모든 노드에서 읽고 쓰기가 가능한 진정한 Multi-Master 구조라는 점이 흥미로웠습니다.
다만, 사용 시 주의해야 할 부분들이 많았습니다.- PK를 지정해야 한다는 점
- PK가 배수로 증가한다는 점
- DDL문은 모든 Cluster성능에 영향을 미친다는 점
- 기존에 알던 Deadlock과 다른 Deadlock이 발생할 수 있다는 점
- 인증 복제로 다중 노드의 Lost Update는 예방할 수 있지만, 많은 데이터 변경으로 인한 Lost Update는 발생할 수 있다는 점
이처럼 많은 개념들을 놓치지 말아야 했고, 모르고 사용하면 문제 발생 후에야 알게 되는 기능들이었습니다.
저도 DB 장애 이후에 저희가 사용하는 기술에 대해 더 많이 알아볼 수 있는 좋은 기회가 되었습니다.
'글또' 카테고리의 다른 글
개발자를 위한 커리어 관리 핸드북 (0) 2025.01.04 2024 회고 (0) 2024.12.22 Mybatis 사용시 return 값을 검사하는 이유는 무엇일까 (0) 2024.12.18 Sharding 만들어보기 (0) 2024.11.24 실시간 리더보드 만들어보기 (0) 2024.11.09
