-
람다와 StreamTIL 2021. 1. 19. 16:10
함수형 프로그래밍이란?
하나의 공정을 하는 함수를 만들어 사용하는 것이다. 단 여러 조건이 붙는(불변성, 1급 시민, 순수 함수 등..)
Java 8과 함수형 프로그래밍: Lambda, Stream, Functional Interface
Intro. 왜 Java 8인가? Java 8 (=Java 1.8) 은 2014년에 발표된 자바 버전이다. 내가 대학에서 자바를 배웠던 것은 Java 8이 발표되기 전이었다. 당연히 Java 8의 신기능에 대해서 대학 수업에서는 배우지 못했
gsmesie692.tistory.com
람다식 이란?
기본 문법 (타입 매개변수,...) -> {실행문;...} , (int a)-> {System.out.println(a);}
지금은 매개변수를 가진 코드블록 이지만 런타임 시에는 익명 구현 객체를 생성함
객체지향 언어보다는 함수 지향 언어에 가깝다.
근데 클래스 멤버를 사용 할 수 있는데 그럼 순수 함수가 아니게 된다 -> 함수형 프로그래밍 x
자바에서 람다를 사용하는 이유 : 코드가 간결하짐, 컬렉션의 요소를 필터링, 매핑이 쉬워짐
람다가 빛을 바라는 것은 인터페이스의 익명 구현 객체를 만들 때이다.
인터페이스는 익명 구현 객체로 사용할 수 있는데 모든 메서드를 구현해야 한다.
근데 람다는 하나의 메서드만 정의하기 때문에 람다가 익명 구현 객체로 만들 수 있는 인터페이스는 함수가 하나 여야 한다.
그래서 인터페이스는 하나의 함수를 가지고 있어야 람다를 통해 익명 구현 객체로 사용이 가능하다.
그 인터페이스를 컴파일 시에 쉽게 체크하기 위해 어노테이션을 제공한다. @FumctionalInterface 안 붙여도 상관은 없지만 다른 누군가가 메서드를 추가하는 것을 막기 위해 사용하는 게 좋다.


기본 구조는 Interface F= (x) -> {...} or x -> {...} 사용은 F.Sum() 람다식 도중에 this를 호출할 수 있는데 그 this는 람다를 호출한 객체의 this이다.
익명 구현 객체라고 그 안에서 생성된 this가 아니라 자신을 호출한 this를 사용한다.
자바에서는 함수적 인터페이스(메서드가 하나인 인터페이스)를 제공하는데 모두 람다로 익명구현 객체로 만들어 사용이 가능 하다. 이전에 다뤄서 다루진 않겠다.
람다식에서는 코드를 더 간결하게 하기 위해 메소드 참조라는 것을 지원한다.
MathInter face=(left, right) -> Math.max (left, right);
MathInter face=Math :: max;
어차피 람다는 매개변수를 전달만 하니까 그냥 다 생략해 버린 거다.
메서드 참조는 정적 메서드 참조, 인스턴스 메서드 참조, 생성자 참도 도 가능하다.
이제 Stream을 알아보자.
Stream은 컬렉션에 저장 요소를 하나씩 참조해서 람다식(함수적-스타일)으로 처리할 수 있도록 해주는 반복자이다.

특징
iterator와 비슷하지만 람다식으로 처리하는 점.
내부 반복자를 사용한다는 점
( 개발자가 작성한 for문은 i값을 신경 써 줘야 한다 -> 외부 반복자 , forEach는 내부적으로 돌기 때문에 개발자가 신경을 안 쓴다 -> 내부 반복자.)

이것이 자바다. 내부 반복자를 사용해서 병렬 처리가 쉽다는 점 -> parallelStream()을 이용
(병렬 처리란 한 가지 작업을 여러 작업으로 나누고 여러 스레드에서 동시다발적으로 실행시키는 것)
물론 Stream 자체는 내부 반복자를 사용해도 하나의 스레드에서 실행이 되지만
stream을 생성할 때 parallelStream을 사용하면 병렬적으로 처리할 수 있다.


병렬 처리 스트림은 각기 다른 스레드에서 실행되는 것을 알 수 있다.
Stream과 함수적 프로그래밍과의 연관성은 무엇인가?
Stream이 제공하는 메서드가 대부분이 매개변수로 함수 인터페이스를 받고 있어서 람다를 통해 익명구현 객체로 사용이 가능하다. 람다를 통해 익명 구현객체로 만들어 사용하면 규칙만 지키면 1급 시민을 만들 수 있다.
또 병렬 처리를 하면 함수형 프로그래밍의 모든 조건을 만족한다. 순수 함수로 인해 외부 값의 영향을 받지 않고 병렬적으로 실행되기도 하고
고로 람다는 java에서 함수적 프로그래밍을 도와주는 역할이고 stream은 함수적 프로그래밍을 쉽게 사용하게 해주는 느낌이다.

함수인터페이스를 매개변수로 받는다. 스트림의 종류에는 Stream, intStream, Long... Double 등이 있다.
스트림을 작성하면 여러 개의 메서드를 사용하게 되는데 그 연결된 모습을 파이프라인이라고 한다.
그 메서드들은 최종 연산이 되기 전까지 lazy(지연)이 된다. 최종연산이 시작되면 그제서야 돌기 시작한다.
만약 앞에서 다 돌아 버렸는데 최종연산이 출력하나 였다면 낭비이니까 lazy 하는 거다.
병렬 처리
병렬 처리의 이유는 실행 시간을 줄이기 위해서 이다.
위에 병렬 처리가 어디서 일어나는지 보면 포크 조인 스레드(스레드 풀)에서 일어난다.
stream에서 병렬 처리를 하면 런타임 시에 포크 조인 프레임워크가 동작하는데 , 그곳에서 데이터들을 나누고(포크) 계산하고 다시 합쳐(조인)해서 결과를 리턴해준다.

https://jihyun-development.tistory.com/37 물론 병렬 처리는 작업을 빠르게 해 주지만 그만큼 성능을 잡아먹는다.
순차적인 stream은 하나의 객체만 바라보고 연산을 수행한다면
병렬적인 stream은 여러 객체를 생성하고 연산하고를 반복해서 성능을 잡아먹는다.
병렬 처리의 성능
항상 병렬 처리가 순차처리보다 성능이 좋다고 판단해서는 안된다. 다음 3개를 판단해야 한다.
요소의 수와 요소당 처리시간
컬렉션에 요소의 수가 적고 요소당 처리 시간이 짧으면 순차 처리가 오히려 병렬 처리보다 빠를 수 있다.
병렬 처리는 스레드 풀 생성 , 스레드 생성이라는 추가 비용이 발생하기에
스트림 소스의 종류
ArrayList나 배열은 인덱스로 요소를 관리하기 때문에 포크 단계에서 쉽게 분리 가능 but set이나 linkedlist는 분리가 쉽지 않다. 따라서 저 두 개는 병렬 처리가 상대적으로 느리다.
코어의 수
싱글코어 cpu일 경우에는 순차처리가 빠르다. 병렬 처리를 하면 스레드 수만 증가하고 동시성 작업(하나의 스레드에서 여러 작업을 번갈아 가며 실행)을 하기에 결과가 안 좋다.
스트림에서의 그룹바이 사용기

아주 쉽게 그룹으로 묶어서 보여 줄 수 있다.
Java Stream Collector 반쪽짜리 스트림을 쓰던 그대에게. Advanced Stream!
Java Stream "Collector" filter, map, reduce, ... 뭐 이 정도? 이번에 "모던 자바 인 액션"이라는 책을 다시 보면서 반쪽짜리 스트림을 쓰고 있었구나... 하는 생각이 들었습니다. 이전에는 filter, map, reduc..
jeong-pro.tistory.com
map과 reduce 사용하기
내가 생각하는 map과 reduce는
map : 값을 하나 꺼내서 거기에 뭔가를 함
reduce : 누적되는 뭔가 있음, 리스트에서 값을 하나 꺼내서 누적된 것과 뭔가를 함
예제를 보자
map 예제
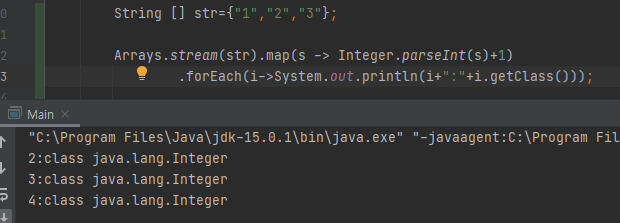
리스트의 값은 String이였지만 map을 만나고 변환하니 Integer가 되었다.
reduce 예제

identity는 초기값이 0 이고 a의 역할을 한다.
b는 리스트에서 하나씩 읽어와 a와 연산을 해 identity에 저장을 한다.
예제에는 문자열 사이에 특정문자를 넣는다던가 max값min값을 reduce로 구하는 예제가 있다.
mkyong.com/java8/java-8-stream-reduce-examples/
Java 8 Stream.reduce() examples - Mkyong.com
- Java 8 Stream.reduce() examples
mkyong.com
collect 사용하기
데이터를 조작하고 원하는 자료형으로 반환
아이템들을 하나의 문자열로 반환
등등..
데이터를 조작하고 원하는 자료형으로 반환
Set으로 반환
ArrayList<Integer> Ar=new ArrayList<>();
Ar.add(1);
Ar.add(1);
Ar.add(2);
Ar.add(2);
Ar.add(3);
Ar.add(3);
Set<Integer> collect = Ar.stream().collect(Collectors.toSet());
for (Integer integer : collect) {
System.out.println(integer);
} // 1 2 3map으로 반환

아이템들을 하나의 문자열로 반환

codechacha.com/ko/java8-stream-collect/
Java8의 Stream Collect 사용 방법 및 예제
Collect는 Stream의 데이터를 변형 등의 처리를 하고 원하는 자료형으로 변환해 줍니다. List 또는 Set 자료형으로 변환하거나, joining 또는 Sorting하여 1개의 객체를 리턴하기도 합니다. 또는 아이템들
codechacha.com
JAVA 8 스트림 튜토리얼
출처: Java 8 Stream Tutorial 이 예제-주도 튜토리얼은 Java 8 스트림에 대한 상세한 개요를 제공한다. 맨 처음 Stream API에 대해서 읽을 때, 난 JAVA I/O의 InputStream과 OutputStream과 비슷하게 들리는 이름 때
wraithkim.wordpress.com
stream의 성능 이슈
madplay.github.io/post/mistakes-when-using-java-streams
자바 스트림 정리: 5. 스트림을 사용할 때 주의할 점
자바 스트림 API를 사용할 때 실수할 수 있는 부분과 고민해볼 점은 무엇이 있을까?
madplay.github.io
www.popit.kr/java8-stream%EC%9D%80-loop%EA%B0%80-%EC%95%84%EB%8B%88%EB%8B%A
Stream 성능 이슈에 관한 시선
velog.io/@adam2/JAVA8%EC%9D%98-%EC%8A%A4%ED%8A%B8%EB%A6%BC-%EC%95%8C%EC%95%84%EB%B3%B4%EA%B8%B0
JAVA8의 스트림 알아보기
스트림은 자바8에 새롭게 추가된 기능으로, 선언형(sql같은 질의형)으로 데이터(컬렉션, 배열, 파일, iterate...)를 처리할 수 있다. 자바8의 함수형 패러다임의 시작으로 람다를 이용해 함수형으로
velog.io
람다와 스트림이 코드를 아름답게 해주지만 성능문제에서는 좋지 못한 평가를 받고 있다.
그래도 코드는 정말 이쁘다.
'TIL' 카테고리의 다른 글
2021.01.21 기록장 (0) 2021.01.20 2021.01.20 기록장 (0) 2021.01.19 2021.01.19 기록장 (0) 2021.01.18 함수형 프로그래밍 (0) 2021.01.18 2021.01.18 기록장 (0) 2021.01.17